Evaluation methods allow model developers, users, and stakeholders to compare the capabilities and limitations of different LLMs, and to understand the scope of their utilities and risks in particular domains (Chang et al., 2024ReferenceChang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P. S., Yang, Q., & Xie, X. (2024). A Survey on Evaluation of Large Language Models. ACM Trans. Intell. Syst. Technol., 15(3). https://doi.org/10.1145/3641289). Evaluations can inform all stages of model development, from mixing pre-training data (Held et al., 2025ReferenceHeld, W., Paranjape, B., Koura, P. S., Lewis, M., Zhang, F., & Mihaylov, T. (2025). Optimizing pretraining data mixtures with llm-estimated utility. arXiv Preprint arXiv:2501.11747.; Mizrahi et al., 2025ReferenceMizrahi, D., Larsen, A. B. L., Allardice, J., Petryk, S., Gorokhov, Y., Li, J., Fang, A., Gardner, J., Gunter, T., & Dehghan, A. (2025). Language models improve when pretraining data matches target tasks. arXiv Preprint arXiv:2507.12466.) to selecting and optimizing reward models for alignment (Frick et al., 2024ReferenceFrick, E., Li, T., Chen, C., Chiang, W.-L., Angelopoulos, A. N., Jiao, J., Zhu, B., Gonzalez, J. E., & Stoica, I. (2024). How to Evaluate Reward Models for RLHF. The Thirteenth International Conference on Learning Representations.; Lambert et al., 2025ReferenceLambert, N., Pyatkin, V., Morrison, J., Miranda, L. J. V., Lin, B. Y., Chandu, K., Dziri, N., Kumar, S., Zick, T., Choi, Y., & others. (2025). Rewardbench: Evaluating reward models for language modeling. Findings of the Association for Computational Linguistics: NAACL 2025, 1755–1797.). After models are trained, evaluations arguably become even more important. They act quality filters to decide whether and how companies deploy models (Liang et al., 2022ReferenceLiang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., & others. (2022). Holistic evaluation of language models. ArXiv Preprint, abs/2211.09110. https://arxiv.org/abs/2211.09110). They inform researchers on the most important and promising directions for model improvement (Srivastava et al., 2022ReferenceSrivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., Brown, A. R., Santoro, A., Gupta, A., Garriga-Alonso, A., & others. (2022). Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. ArXiv Preprint, abs/2206.04615. https://arxiv.org/abs/2206.04615), and help anticipate models’ future capabilities (Hoffmann et al., 2022ReferenceHoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. de L., Hendricks, L. A., Welbl, J., Clark, A., & others. (2022). Training compute-optimal large language models. ArXiv Preprint, abs/2203.15556. https://arxiv.org/abs/2203.15556; Kaplan et al., 2020ReferenceKaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling laws for neural language models. ArXiv Preprint, abs/2001.08361. https://arxiv.org/abs/2001.08361). And finally, they shape public perceptions (Liao & Sundar, 2022ReferenceLiao, Q. V., & Sundar, S. S. (2022). Designing for responsible trust in AI systems: A communication perspective. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 1257–1268.), and inform policy and other regulatory decisions (Eriksson et al., 2025ReferenceEriksson, M., Purificato, E., Noroozian, A., Vinagre, J., Chaslot, G., Gomez, E., & Fernandez-Llorca, D. (2025). Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(1), 850–864.).
Without a human-centered evaluation of LLMs, model development, deployment, and governance may be oriented not towards the long-term and collective good, but rather towards profit incentives and short-term gains on surface-level heuristics (Eriksson et al., 2025ReferenceEriksson, M., Purificato, E., Noroozian, A., Vinagre, J., Chaslot, G., Gomez, E., & Fernandez-Llorca, D. (2025). Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(1), 850–864.). In this chapter, we observe common pitfalls and highlight best practices in human-centered evaluation, spanning three levels as shown in the figure. First, we consider evaluations at the level of model outputs (Model-Level Evaluations), using both quantitative metrics (Quantitative Evaluation) and qualitative evaluations (Qualitative Evaluation). Beyond raw outputs, we also consider how people experience LLMs (Human-Level Evaluations), considering human values (Human Values), as well as concerns over bias (Bias and Fairness Evaluation) and safety (Safety Evaluations). Lastly, we discuss extrinsic evaluations at the societal level (Societal-level Evaluation), measuring the system’s real world impact.
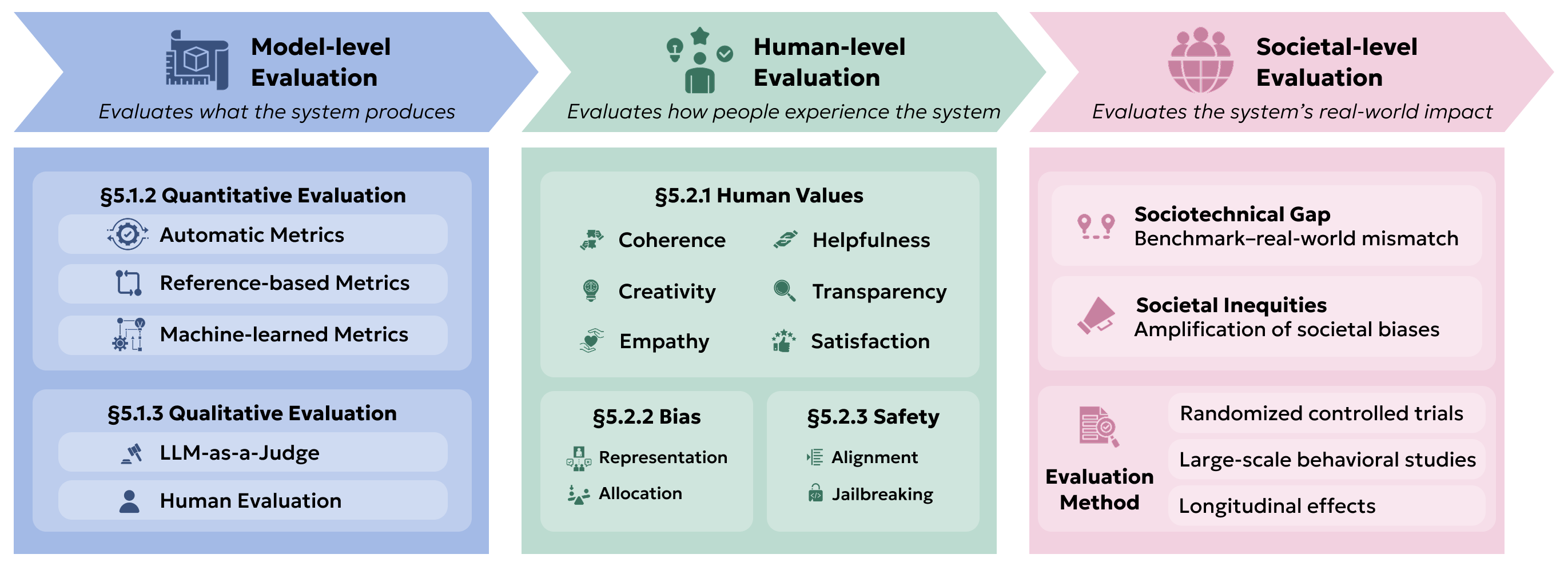
Figure. In this chapter, we discuss common pitfalls and best practices for evaluating HCLLMs, considering three distinct levels of evaluation: the model level (Model-Level Evaluations), the human level (Human-Level Evaluations), and the societal level (Societal-level Evaluation).