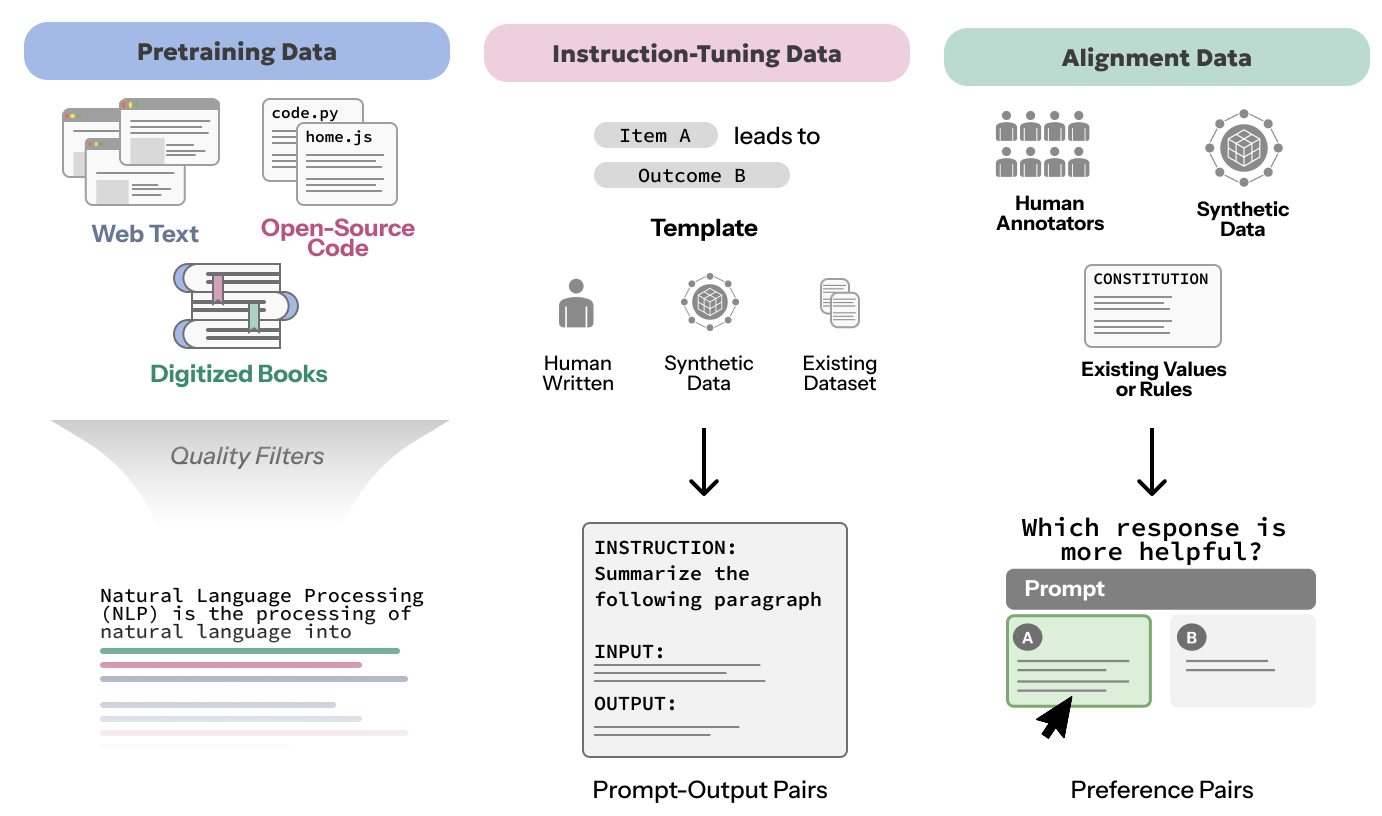
Figure. This chapter focuses on the human origins of data (Data Provenance), and how data encodes perspectives and values that impact HCLLM outcomes, from representation and bias (Data Representation, Bias and Ethics) to consent and ownership (Consent and Ownership). In particular, we consider pre-training data, instruction-tuning data, and alignment data.
Data provenance (Longpre et al., 2023ReferenceLongpre, S., Mahari, R., Chen, A., Obeng-Marnu, N., Sileo, D., Brannon, W., Muennighoff, N., Khazam, N., Kabbara, J., Perisetla, K., & others. (2023). The Data Provenance Initiative: A Large Scale Audit of Dataset Licensing & Attribution in AI.), also called dataset genealogy (Denton et al., 2021ReferenceDenton, E., Hanna, A., Amironesei, R., Smart, A., & Nicole, H. (2021). On the genealogy of machine learning datasets: A critical history of ImageNet. Big Data & Society, 8(2), 20539517211035955.), is the record of a dataset’s origins, history, and transformations throughout its lifecycle. An understanding of data provenance is critical for achieving transparency in LLM development (Bommasani et al., 2023ReferenceBommasani, R., Klyman, K., Longpre, S., Kapoor, S., Maslej, N., Xiong, B., Zhang, D., & Liang, P. (2023). The foundation model transparency index. ArXiv Preprint, abs/2310.12941. https://arxiv.org/abs/2310.12941). Without transparent data practices, it becomes difficult to predict and understand why LLMs leak private information (Bubeck et al., 2023ReferenceBubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., & Zhang, Y. (2023). Sparks of Artificial General Intelligence: Early experiments with GPT-4. https://arxiv.org/abs/2303.12712; Kandpal et al., 2022ReferenceKandpal, N., Wallace, E., & Raffel, C. (2022). Deduplicating Training Data Mitigates Privacy Risks in Language Models. In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvári, G. Niu, & S. Sabato (Eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Vol. 162, pp. 10697–10707). PMLR. https://proceedings.mlr.press/v162/kandpal22a.html), violate copyrights (Carlini et al., 2021ReferenceCarlini, N., Tramer, F., Wallace, E., Jagielski, M., Herbert-Voss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlingsson, U., & others. (2021). Extracting training data from large language models. 30th USENIX Security Symposium (USENIX Security 21), 2633–2650.), or perpetuate social biases (Denton et al., 2021ReferenceDenton, E., Hanna, A., Amironesei, R., Smart, A., & Nicole, H. (2021). On the genealogy of machine learning datasets: A critical history of ImageNet. Big Data & Society, 8(2), 20539517211035955.). But with data provenance, stakeholders become more equipped to audit models (Mökander et al., 2024ReferenceMökander, J., Schuett, J., Kirk, H. R., & Floridi, L. (2024). Auditing large language models: a three-layered approach. AI and Ethics, 4(4), 1085–1115.) and tackle these human-centered concerns. In this section, we will investigate the provenance of data used for pre-training, instruction-tuning, and aligning LLMs. In particular, we ask where data comes from, who produced it, and under what conditions it was produced.
Pretraining Data
Data Sources. The provenance of LLM pretraining data is often complex, layered, and opaque. Unlike the small, curated datasets of traditional machine learning, LLM pretraining corpora tend to be huge, multi-trillion token aggregations across heterogeneous and potentially noisy sources. These sources traditionally include web text, digitized books, and open-source code repositories (Devlin et al., 2019ReferenceDevlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In J. Burstein, C. Doran, & T. Solorio (Eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171–4186). Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1423; Raffel et al., 2020ReferenceRaffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res., 21, 140:1-140:67. http://jmlr.org/papers/v21/20-074.html; Soldaini et al., 2024ReferenceSoldaini, L., Kinney, R., Bhagia, A., Schwenk, D., Atkinson, D., Authur, R., Bogin, B., Chandu, K., Dumas, J., Elazar, Y., Hofmann, V., Jha, A. H., Kumar, S., Lucy, L., Lyu, X., Lambert, N., Magnusson, I., Morrison, J., Muennighoff, N., … Lo, K. (2024). Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. In ArXiv preprint: Vol. abs/2402.00159. https://arxiv.org/abs/2402.00159; Wenzek et al., 2020ReferenceWenzek, G., Lachaux, M.-A., Conneau, A., Chaudhary, V., Guzmán, F., Joulin, A., & Grave, E. (2020). CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 4003–4012). European Language Resources Association. https://aclanthology.org/2020.lrec-1.494). Although different model developers use different data mixtures, most incorporate an open web crawl that at least partially intersects the Common Crawl. The Common Crawl contains monthly snapshots of “open web”—partial samples of machine-crawlable sites reached from seed URLs that were initially crowdsourced in 2008 (Baack, 2024ReferenceBaack, S. (2024). A critical analysis of the largest source for generative ai training data: Common crawl. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, 2199–2208.). This is not a random sample of the internet. Large web crawls like this favor wikis, news sites, blogs, and other user-generated content platforms, which are generally multilingual, but heavily skew towards English (Baack, 2024ReferenceBaack, S. (2024). A critical analysis of the largest source for generative ai training data: Common crawl. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, 2199–2208.). Much of this data has been found to be socially undesirable, with a high prevalence of hate speech and sexually explicit content (Luccioni & Viviano, 2021ReferenceLuccioni, A. S., & Viviano, J. D. (2021). What’s in the Box? A Preliminary Analysis of Undesirable Content in the Common Crawl Corpus. In ArXiv preprint: Vol. abs/2105.02732. https://arxiv.org/abs/2105.02732). The data can also reify social, cultural, and political biases . Finally, this web-scale data inextricably encodes the structural biases of the web itself, where the majority of content is produced by an active minority of users, and these users overly represent Western, Educated, Industrialized, Rich and Democratic (WEIRD) populations (Baeza-Yates, 2018ReferenceBaeza-Yates, R. (2018). Bias on the web. Communications of the ACM, 61(6), 54–61.).
Quality Filtering. Because open web data is noisy, redundant, low-quality, and often socially undesirable, model developers use classifiers or heuristics (Chen et al., 2021ReferenceChen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., … Zaremba, W. (2021). Evaluating Large Language Models Trained on Code. https://arxiv.org/abs/2107.03374; Penedo et al., 2023ReferencePenedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cappelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., & Launay, J. (2023). The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only. arXiv Preprint arXiv:2306.01116. https://arxiv.org/abs/2306.01116; Rae et al., 2021ReferenceRae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., Aslanides, J., Henderson, S., Ring, R., Young, S., & others. (2021). Scaling language models: Methods, analysis & insights from training gopher. ArXiv Preprint, abs/2112.11446. https://arxiv.org/abs/2112.11446; Soldaini et al., 2024ReferenceSoldaini, L., Kinney, R., Bhagia, A., Schwenk, D., Atkinson, D., Authur, R., Bogin, B., Chandu, K., Dumas, J., Elazar, Y., Hofmann, V., Jha, A. H., Kumar, S., Lucy, L., Lyu, X., Lambert, N., Magnusson, I., Morrison, J., Muennighoff, N., … Lo, K. (2024). Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research. In ArXiv preprint: Vol. abs/2402.00159. https://arxiv.org/abs/2402.00159) to filter their pre-training corpora for unique and high-quality documents that are information dense and free from toxicity or personally identifiable information (Longpre et al., 2024ReferenceLongpre, S., Biderman, S., Albalak, A., Schoelkopf, H., McDuff, D., Kapoor, S., Klyman, K., Lo, K., Ilharco, G., San, N., & others. (2024). The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources. Transactions on Machine Learning Research.). By filtering pre-training data in this way, researchers can train safer models with better performance at lower computational costs (Albalak et al., 2024ReferenceAlbalak, A., Elazar, Y., Xie, S. M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., & others. (2024). A survey on data selection for language models. ArXiv Preprint, abs/2402.16827. https://arxiv.org/abs/2402.16827; Du et al., 2022ReferenceDu, N., Huang, Y., Dai, A. M., Tong, S., Lepikhin, D., Xu, Y., Krikun, M., Zhou, Y., Yu, A. W., Firat, O., Zoph, B., Fedus, L., Bosma, M. P., Zhou, Z., Wang, T., Wang, Y. E., Webster, K., Pellat, M., Robinson, K., … Cui, C. (2022). GLaM: Efficient Scaling of Language Models with Mixture-of-Experts. In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvári, G. Niu, & S. Sabato (Eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Vol. 162, pp. 5547–5569). PMLR. https://proceedings.mlr.press/v162/du22c.html; Rae et al., 2021ReferenceRae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., Aslanides, J., Henderson, S., Ring, R., Young, S., & others. (2021). Scaling language models: Methods, analysis & insights from training gopher. ArXiv Preprint, abs/2112.11446. https://arxiv.org/abs/2112.11446). The distributions of these filtered corpora are shaped by sampling decisions, including the filters used to determine document quality. These quality filters often systematically exclude both communities and discursive topics (Lucy et al., 2024ReferenceLucy, L., Gururangan, S., Soldaini, L., Strubell, E., Bamman, D., Klein, L., & Dodge, J. (2024). AboutMe: Using Self-Descriptions in Webpages to Document the Effects of English Pretraining Data Filters. In L.-W. Ku, A. Martins, & V. Srikumar (Eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 7393–7420). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.400). For instance, toxicity classifiers often exhibit racial and linguistic bias (Dodge et al., 2021ReferenceDodge, J., Sap, M., Marasović, A., Agnew, W., Ilharco, G., Groeneveld, D., Mitchell, M., & Gardner, M. (2021). Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. In M.-F. Moens, X. Huang, L. Specia, & S. W. Yih (Eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 1286–1305). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.emnlp-main.98; Sap et al., 2019ReferenceSap, M., Card, D., Gabriel, S., Choi, Y., & Smith, N. A. (2019). The risk of racial bias in hate speech detection. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 1668–1678.). Quality filters trained on Wikipedia and OpenWebText tend to favor text from wealthy, educated, urban areas (Gururangan et al., 2022ReferenceGururangan, S., Card, D., Dreier, S., Gade, E., Wang, L., Wang, Z., Zettlemoyer, L., & Smith, N. A. (2022). Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection. In Y. Goldberg, Z. Kozareva, & Y. Zhang (Eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 2562–2580). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.emnlp-main.165).
After language identification (Conneau & Lample, 2019ReferenceConneau, A., & Lample, G. (2019). Cross-lingual Language Model Pretraining. In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, & R. Garnett (Eds.), Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada (pp. 7057–7067). https://proceedings.neurips.cc/paper/2019/hash/c04c19c2c2474dbf5f7ac4372c5b9af1-Abstract.html; Laurençon et al., 2022ReferenceLaurençon, H., Saulnier, L., Wang, T., Akiki, C., Villanova del Moral, A., Le Scao, T., Von Werra, L., Mou, C., González Ponferrada, E., Nguyen, H., & others. (2022). The bigscience roots corpus: A 1.6 tb composite multilingual dataset. Advances in Neural Information Processing Systems, 35, 31809–31826.) and deduplication (Lee et al., 2022ReferenceLee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., & Carlini, N. (2022). Deduplicating Training Data Makes Language Models Better. In S. Muresan, P. Nakov, & A. Villavicencio (Eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 8424–8445). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.577), model-based filtering is one popular quality filtering approach. For example, perplexity-based methods filter noisy documents that appear as highly surprising to a much smaller language model. CCNet (Wenzek et al., 2020ReferenceWenzek, G., Lachaux, M.-A., Conneau, A., Chaudhary, V., Guzmán, F., Joulin, A., & Grave, E. (2020). CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 4003–4012). European Language Resources Association. https://aclanthology.org/2020.lrec-1.494) was constructed as a subset of the Common Crawl, filtered with 5-gram language models that the authors trained on Wikipedia data for each target language. They use a fastText classifier (Joulin et al., 2017ReferenceJoulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2017). Bag of tricks for efficient text classification. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 427–431.) for language identification and run each deduplicated document through the appropriate 5-gram model to compute perplexity, filtering based on a heuristic and language-specific perplexity threshold. Disconcertingly, this pipeline effectively filters out minority dialects and low-resource languages (Albalak et al., 2024ReferenceAlbalak, A., Elazar, Y., Xie, S. M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., & others. (2024). A survey on data selection for language models. ArXiv Preprint, abs/2402.16827. https://arxiv.org/abs/2402.16827) for which language ID is unreliable (Caswell et al., 2020ReferenceCaswell, I., Breiner, T., van Esch, D., & Bapna, A. (2020). Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus. In D. Scott, N. Bel, & C. Zong (Eds.), Proceedings of the 28th International Conference on Computational Linguistics (pp. 6588–6608). International Committee on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.579; Kudugunta et al., 2023ReferenceKudugunta, S., Caswell, I., Zhang, B., Garcia, X., Xin, D., Kusupati, A., Stella, R., Bapna, A., & Firat, O. (2023). Madlad-400: A multilingual and document-level large audited dataset. Advances in Neural Information Processing Systems, 36, 67284–67296.), or the perplexity model is overfit to only a small corpus (Feng et al., 2023ReferenceFeng, S., Park, C. Y., Liu, Y., & Tsvetkov, Y. (2023). From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models. In A. Rogers, J. Boyd-Graber, & N. Okazaki (Eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 11737–11762). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-long.656; Lucy et al., 2024ReferenceLucy, L., Gururangan, S., Soldaini, L., Strubell, E., Bamman, D., Klein, L., & Dodge, J. (2024). AboutMe: Using Self-Descriptions in Webpages to Document the Effects of English Pretraining Data Filters. In L.-W. Ku, A. Martins, & V. Srikumar (Eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 7393–7420). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.400). Perplexity-based filtering will retain text that matches the language distribution the filtering model was fit to. When the standard is Wikipedia, filtering will primarily preserve Standard American English in the third person, written in a neutral, semi-formal and broadly readable register, with clear declarative sentences. Another idea is to prompt existing LLMs to estimate the quality of pre-training data zero-shot using some manually-written definition of high quality data (Penedo et al., 2024ReferencePenedo, G., Kydlı́ček, H., Lozhkov, A., Mitchell, M., Raffel, C. A., Von Werra, L., Wolf, T., & others. (2024). The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems, 37, 30811–30849.; Sachdeva et al., 2024ReferenceSachdeva, N., Coleman, B., Kang, W.-C., Ni, J., Hong, L., Chi, E. H., Caverlee, J., McAuley, J., & Cheng, D. Z. (2024). How to train data-efficient llms. arXiv Preprint arXiv:2402.09668.; Wettig et al., 2024ReferenceWettig, A., Gupta, A., Malik, S., & Chen, D. (2024). Qurating: Selecting high-quality data for training language models. arXiv Preprint arXiv:2402.09739.). This was the approach used for Llama-3 (AI@Meta, 2024ReferenceAI@Meta. (2024). Llama 3 Model Card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md). However, manually-written definitions are brittle and may not encompass task-specific or user-specific notions of LLM utility (Held et al., 2025ReferenceHeld, W., Paranjape, B., Koura, P. S., Lewis, M., Zhang, F., & Mihaylov, T. (2025). Optimizing pretraining data mixtures with llm-estimated utility. arXiv Preprint arXiv:2501.11747.). A third idea is to fine-tune a small model like fastText (Joulin et al., 2017ReferenceJoulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2017). Bag of tricks for efficient text classification. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, 427–431.) as a binary quality classifier. The binary classifier was the approach used by DataComp for Language Models (Li et al., 2024ReferenceLi, J., Fang, A., Smyrnis, G., Ivgi, M., Jordan, M., Gadre, S. Y., Bansal, H., Guha, E., Keh, S. S., Arora, K., & others. (2024). Datacomp-lm: In search of the next generation of training sets for language models. Advances in Neural Information Processing Systems, 37, 14200–14282.), as this resulted in models with higher scores on general benchmarks like MMLU (Hendrycks et al., 2021ReferenceHendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2021). Measuring Massive Multitask Language Understanding. International Conference on Learning Representations.). However, methods like this are prone to overfitting on the training set, the construction of which itself reflects and reifies the values of model developers.
Another popular filtering mechanism is to use content heuristics like domain name blacklists, and toxic keyword dictionaries, which were used to construct the Colossal Clean Crawled Corpus (C4) (Raffel et al., 2020ReferenceRaffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res., 21, 140:1-140:67. http://jmlr.org/papers/v21/20-074.html; Xue et al., 2021ReferenceXue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., & Raffel, C. (2021). mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 483–498.). The English C4 was found to skew heavily towards Wikipedia articles, patents, and United States news articles, such as the New York Times (Dodge et al., 2021ReferenceDodge, J., Sap, M., Marasović, A., Agnew, W., Ilharco, G., Groeneveld, D., Mitchell, M., & Gardner, M. (2021). Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. In M.-F. Moens, X. Huang, L. Specia, & S. W. Yih (Eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 1286–1305). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.emnlp-main.98; Elazar et al., 2024ReferenceElazar, Y., Bhagia, A., Magnusson, I., Ravichander, A., Schwenk, D., Suhr, A., Walsh, E. P., Groeneveld, D., Soldaini, L., Singh, S., & others. (2024). What’s In My Big Data? ICLR.). Most documents in the corpus had been published after the year 2011. The multilingual variant, mC4 (Xue et al., 2021ReferenceXue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., & Raffel, C. (2021). mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 483–498.), represents 101 identified languages, but many of these languages are under-represented (Snæbjarnarson et al., 2022ReferenceSnæbjarnarson, V., Sı́monarson, H. B., Ragnarsson, P. O., Ingólfsdóttir, S. L., Jónsson, H., Þorsteinsson, V., & Einarsson, H. (2022). A Warm Start and a Clean Crawled Corpus-A Recipe for Good Language Models. Proceedings of the Thirteenth Language Resources and Evaluation Conference, 4356–4366.). For example, compared to 2.7T tokens of English, mC4 contains only 600,000 tokens of Javanese (Aji et al., 2022ReferenceAji, A. F., Winata, G. I., Koto, F., Cahyawijaya, S., Romadhony, A., Mahendra, R., Kurniawan, K., Moeljadi, D., Prasojo, R. E., Baldwin, T., & others. (2022). One Country, 700+ Languages: NLP Challenges for Underrepresented Languages and Dialects in Indonesia. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 7226–7249.). Data for these lower-resource languages is also much noisier than that of the English subset (Kreutzer et al., 2022ReferenceKreutzer, J., Caswell, I., Wang, L., Wahab, A., Van Esch, D., Ulzii-Orshikh, N., Tapo, A., Subramani, N., Sokolov, A., Sikasote, C., & others. (2022). Quality at a glance: An audit of web-crawled multilingual datasets. Transactions of the Association for Computational Linguistics, 10, 50–72.; van Noord et al., 2024Referencevan Noord, R., Kuzman, T., Rupnik, P., Ljubesic, N., Esplà-Gomis, M., Ramı́rez-Sánchez, G., & Toral, A. (2024). Do Language Models Care about Text Quality? Evaluating Web-Crawled Corpora across 11 Languages. LREC/COLING.).
Many pretraining corpora aggregate documents from a variety of sources. Popular examples include the Pile (Gao et al., 2021ReferenceGao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., & Leahy, C. (2021). The Pile: An 800GB Dataset of Diverse Text for Language Modeling. In ArXiv preprint: Vol. abs/2101.00027. https://arxiv.org/abs/2101.00027), RedPajama (Weber et al., 2024ReferenceWeber, M., Fu, D., Anthony, Q., Oren, Y., Adams, S., Alexandrov, A., Lyu, X., Nguyen, H., Yao, X., Adams, V., & others. (2024). Redpajama: an open dataset for training large language models. Advances in Neural Information Processing Systems, 37, 116462–116492.), and Nemotron-CC (Su et al., 2025ReferenceSu, D., Kong, K., Lin, Y., Jennings, J., Norick, B., Kliegl, M., Patwary, M., Shoeybi, M., & Catanzaro, B. (2025). Nemotron-cc: Transforming common crawl into a refined long-horizon pretraining dataset. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2459–2475.), which contain 300B, 1T, and 7T tokens respectively, sampled from the Common Crawl, as well as academic texts, books, coding, medical, and legal documents (Biderman et al., 2022ReferenceBiderman, S., Bicheno, K., & Gao, L. (2022). Datasheet for the pile. arXiv Preprint arXiv:2201.07311.; Weber et al., 2024ReferenceWeber, M., Fu, D., Anthony, Q., Oren, Y., Adams, S., Alexandrov, A., Lyu, X., Nguyen, H., Yao, X., Adams, V., & others. (2024). Redpajama: an open dataset for training large language models. Advances in Neural Information Processing Systems, 37, 116462–116492.). Over half of the documents in these data mixes are duplicated at least once, and some of these contain personally identifiable information like email and IP addresses, as well as toxic language (Elazar et al., 2024ReferenceElazar, Y., Bhagia, A., Magnusson, I., Ravichander, A., Schwenk, D., Suhr, A., Walsh, E. P., Groeneveld, D., Soldaini, L., Singh, S., & others. (2024). What’s In My Big Data? ICLR.).
Instruction-tuning Data
Compared to the origin story of pre-training data, the provenance of instruction-tuning datasets is relatively well-known. Data is typically aggregated by a single organization for the purpose of fine-tuning a model to follow instructions. Therefore the provenance of instruction dataset development resembles the distribution of model developers, over half of whom originate in the US or China (Held et al., 2023ReferenceHeld, W., Harris, C., Best, M., & Yang, D. (2023). A material lens on coloniality in nlp. arXiv Preprint arXiv:2311.08391.). Notable examples include Google’s FLAN (Chung et al., 2024ReferenceChung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., & others. (2024). Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70), 1–53.), AI2’s Natural Instructions (Mishra et al., 2022ReferenceMishra, S., Khashabi, D., Baral, C., & Hajishirzi, H. (2022). Cross-Task Generalization via Natural Language Crowdsourcing Instructions. In S. Muresan, P. Nakov, & A. Villavicencio (Eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 3470–3487). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.244), Stanford’s Alpaca (Taori et al., 2023ReferenceTaori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., & Tatsunori B. Hashimoto. (2023). Stanford Alpaca: An Instruction-following LLaMA model. In GitHub repository. GitHub. https://github.com/tatsu-lab/stanford_alpaca), and Cohere’s Aya corpus (Singh et al., 2024ReferenceSingh, S., Vargus, F., Dsouza, D., Karlsson, B. F., Mahendiran, A., Ko, W.-Y., Shandilya, H., & others. (2024). Aya dataset: An open-access collection for multilingual instruction tuning. ArXiv Preprint, abs/2402.06619. https://arxiv.org/abs/2402.06619).
The instruction aggregation process often involves selecting a diverse range of tasks over which are constructed well-formatted prompt-output pairs. Some organizations may opt to annotate these pairs entirely from scratch, like in the Databricks (2023)ReferenceDatabricks. (2023). Databricks Dolly 15k: An open instruction-tuned dataset. https://github.com/databricks/dolly Dolly-15k. There are ethical and scientific benefits in such cases where data is sourced with explicit consent, attribution, and compensation. However, this is not the norm, especially since doing so demands significant human labor.
In many cases, instructions are sourced automatically from evaluation benchmarks via templates (Chung et al., 2024ReferenceChung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., & others. (2024). Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70), 1–53.; Longpre, Hou, et al., 2023)ReferenceLongpre, S., Hou, L., Vu, T., Webson, A., Chung, H. W., Tay, Y., Zhou, D., Le, Q. V., Zoph, B., Wei, J., & Roberts, A. (2023). The Flan Collection: Designing Data and Methods for Effective Instruction Tuning. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, & J. Scarlett (Eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Vol. 202, pp. 22631–22648). PMLR. https://proceedings.mlr.press/v202/longpre23a.html, which may be further translated (Muennighoff et al., 2023ReferenceMuennighoff, N., Wang, T., Sutawika, L., Roberts, A., Biderman, S., Le Scao, T., Bari, M. S., Shen, S., Yong, Z. X., Schoelkopf, H., Tang, X., Radev, D., Aji, A. F., Almubarak, K., Albanie, S., Alyafeai, Z., Webson, A., Raff, E., & Raffel, C. (2023). Crosslingual Generalization through Multitask Finetuning. In A. Rogers, J. Boyd-Graber, & N. Okazaki (Eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 15991–16111). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-long.891) or restructured using tertiary models. The templates themselves typically have a human origin. For example, the Natural Instructions dataset (Mishra et al., 2022ReferenceMishra, S., Khashabi, D., Baral, C., & Hajishirzi, H. (2022). Cross-Task Generalization via Natural Language Crowdsourcing Instructions. In S. Muresan, P. Nakov, & A. Villavicencio (Eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 3470–3487). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.244) was sourced from annotation guidelines that the benchmark developers constructed to onboard crowdworkers. Sometimes, humans also write templates from scratch, especially in the early days of UnifiedQA (Khashabi et al., 2020ReferenceKhashabi, D., Min, S., Khot, T., Sabharwal, A., Tafjord, O., Clark, P., & Hajishirzi, H. (2020). UNIFIEDQA: Crossing Format Boundaries with a Single QA System. Findings of the Association for Computational Linguistics: EMNLP 2020, 1896–1907.) and FLAN (Wei et al., 2022ReferenceWei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., & Le, Q. V. (2022). Finetuned Language Models are Zero-Shot Learners. The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. https://openreview.net/forum?id=gEZrGCozdqR), and in low-resource settings like the multi-lingual Aya corpus (Singh et al., 2024ReferenceSingh, S., Vargus, F., Dsouza, D., Karlsson, B. F., Mahendiran, A., Ko, W.-Y., Shandilya, H., & others. (2024). Aya dataset: An open-access collection for multilingual instruction tuning. ArXiv Preprint, abs/2402.06619. https://arxiv.org/abs/2402.06619). However, much of the data construction pipeline is automated. This trend is growing as instruction-tuning datasets are generated synthetically. For example, the instructions used to fine-tune Stanford’s Alpaca model (Taori et al., 2023ReferenceTaori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., & Tatsunori B. Hashimoto. (2023). Stanford Alpaca: An Instruction-following LLaMA model. In GitHub repository. GitHub. https://github.com/tatsu-lab/stanford_alpaca) were distilled from GPT-3.5, a larger model which was itself instruction-fine-tuned. This approach, called self-instruction tuning (Wang et al., 2023ReferenceWang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., & Hajishirzi, H. (2023). Self-Instruct: Aligning Language Models with Self-Generated Instructions. In A. Rogers, J. Boyd-Graber, & N. Okazaki (Eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 13484–13508). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-long.754), has been adopted in a range of more recent work (B. Li et al., 2025ReferenceLi, B., Zhang, Y., Chen, L., Wang, J., Pu, F., Cahyono, J. A., Yang, J., Li, C., & Liu, Z. (2025). Otter: A multi-modal model with in-context instruction tuning. IEEE Transactions on Pattern Analysis and Machine Intelligence.; Peng et al., 2023ReferencePeng, B., Li, C., He, P., Galley, M., & Gao, J. (2023). Instruction Tuning with GPT-4. ArXiv Preprint, abs/2304.03277. https://arxiv.org/abs/2304.03277). As we will discuss in Expanding Data Sources: Synthetic and Non-Traditional Data, the use of synthetic data for self-instruction tuning complicates data provenance, and may exacerbate the human-centered concerns raised in this chapter.
Alignment Data
Additional datasets are used for model alignment, or the process of training more helpful and less harmful models via supervised fine-tuning, preference tuning, and reinforcement learning from human feedback (RLHF) (Askell et al., 2021ReferenceAskell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Kernion, J., Ndousse, K., Olsson, C., Amodei, D., Brown, T., Clark, J., … Kaplan, J. (2021). A General Language Assistant as a Laboratory for Alignment. In ArXiv preprint: Vol. abs/2112.00861. https://arxiv.org/abs/2112.00861). Since alignment data is what produces models that are useful to humans, it constitutes a major force behind the sudden proliferation in the number of LLM users worldwide.
Since the notion of helpfulness or harmfulness is ambiguous and varies with different cultures and contexts, one might expect a commensurate heterogeneity in both the source and format of alignment data (Ethayarajh, 2024ReferenceEthayarajh, K. (2024). Behavior-Bound Machine Learning [Phdthesis]. Stanford University.). This is generally not the case. With respect to the format, many alignment datasets assume a Bradley—Terry model of pairwise human preferences. Datasets like Anthropic’s HH-RLHF (Bai et al., 2022ReferenceBai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., … Kaplan, J. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. In ArXiv preprint: Vol. abs/2204.05862. https://arxiv.org/abs/2204.05862), OpenAI’s InstructGPT (Ouyang et al., 2022ReferenceOuyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, & A. Oh (Eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022. http://papers.nips.cc/paper%5C_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html), and Peking University’s PKU-SafeRLHF (Ji et al., 2023ReferenceJi, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., Chen, B., Sun, R., Wang, Y., & Yang, Y. (2023). BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, & S. Levine (Eds.), Advances in Neural Information Processing Systems (Vol. 36, pp. 24678–24704). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2023/file/4dbb61cb68671edc4ca3712d70083b9f-Paper-Datasets_and_Benchmarks.pdf) couple a user prompt with a pair of model responses: one preferred and one dispreferred. With respect to data sources, many preference judgments come from a very small pool of annotators, sometimes within the organization itself. For example, Peking University hired 28 internal annotators to construct PKU-SafeRLHF, and Anthropic’s internal research team similarly hired and trained a small group of contractors to construct HH-RLHF.
Crowdsourcing and citizen science can serve to democratize the process of collecting alignment data. One drawback of these approaches is sampling bias, which may favor researchers, AI enthusiasts, and individuals from industrialized nations. Chatbot Arena (Chiang et al., 2024ReferenceChiang, W.-L., Zheng, L., Sheng, Y., Angelopoulos, A. N., Li, T., Li, D., Zhu, B., Zhang, H., Jordan, M. I., Gonzalez, J. E., & Stoica, I. (2024). Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. ICML. https://openreview.net/forum?id=3MW8GKNyzI), also known as LMArena, is one example of a public web platform with open-user participation in which volunteers engage with pairs of anonymous models and provide preference feedback in the standard binary format. The project was initiated at the University of California Berkeley in 2023, and covers 96 languages, although the vast majority are in English. OpenAssistant Conversations (Köpf et al., 2023ReferenceKöpf, A., Kilcher, Y., Von Rütte, D., Anagnostidis, S., Tam, Z. R., Stevens, K., Barhoum, A., Nguyen, D., Stanley, O., Nagyfi, R., & others. (2023). Openassistant conversations-democratizing large language model alignment. Advances in Neural Information Processing Systems, 36, 47669–47681.) is a similar crowdsourcing effort, initiated by the German non-profit LAION in 2022. Over 13k volunteers contributed alignment data in 35 different languages, particularly in English (50%), German (20%), and Spanish (10%). Of these annotators, 89.1% identified as male, with a median age of 26. These clear demographic biases above will skew the values, perspectives, and interests represented by this data.
To address issues of demographic bias, some dataset developers intentionally target underrepresented demographics in their recruitment efforts. For example, the PRISM Alignment Dataset (Kirk et al., 2024ReferenceKirk, H. R., Whitefield, A., Röttger, P., Bean, A. M., Margatina, K., Mosquera, R., Ciro, J. M., Bartolo, M., Williams, A., He, H., Vidgen, B., & Hale, S. A. (2024). The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models. The Thirty-Eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=DFr5hteojx) is an academic project initiated at the University of Oxford, where the developers recruited Prolific workers from 33 underrepresented countries. The Meta Community Alignment Dataset (Zhang et al., 2026ReferenceZhang, L. H., Milli, S., Jusko, K. L., Smith, J., Amos, B., Bouaziz, W., Kussman, J., Revel, M., Titus, L., Radharapu, B., & others. (2026). Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment Dataset. ICLR.) is a similarly-motivated multilingual preference dataset in which its 15k participants were recruited from five countries on YouGov. Still, there remain limitations in recruiting diverse populations from crowdwork platforms, which have limited global coverage (Douglas et al., 2023ReferenceDouglas, B. D., Ewell, P. J., & Brauer, M. (2023). Data quality in online human-subjects research: Comparisons between MTurk, Prolific, CloudResearch, Qualtrics, and SONA. PLOS ONE, 18(3), 1–17. https://doi.org/10.1371/journal.pone.0279720; Palan & Schitter, 2018ReferencePalan, S., & Schitter, C. (2018). Prolific. ac—A subject pool for online experiments. Journal of Behavioral and Experimental Finance, 17, 22–27.; Rinderknecht et al., 2025ReferenceRinderknecht, R. G., Doan, L., & Sayer, L. C. (2025). The Daily Lives of Crowdsourced US Respondents: A Time Use Comparison of MTurk, Prolific, and ATUS. Sociological Methodology, 00811750241312226.).
Synthetic data is an emerging trend among subsections in this chapter, and it is largely motivated by the need to scale AI beyond what human annotation labor can support (Casper et al., 2023ReferenceCasper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., Freedman, R., Korbak, T., Lindner, D., Freire, P., Wang, T., Marks, S., Segerie, C.-R., Carroll, M., Peng, A., Christoffersen, P., Damani, M., Slocum, S., Anwar, U., … Hadfield-Menell, D. (2023). Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. In ArXiv preprint: Vol. abs/2307.15217. https://arxiv.org/abs/2307.15217; Santurkar et al., 2023ReferenceSanturkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (2023). Whose Opinions Do Language Models Reflect? In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, & J. Scarlett (Eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Vol. 202, pp. 29971–30004). PMLR. https://proceedings.mlr.press/v202/santurkar23a.html). Some LLM developers have considered synthetic data in the alignment step as well. Variants of this approach include Constitutional AI (Bai, Kadavath, et al., 2022ReferenceBai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., Chen, C., Olsson, C., Olah, C., Hernandez, D., Drain, D., Ganguli, D., Li, D., Tran-Johnson, E., Perez, E., … Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. ArXiv, abs/2212.08073. https://api.semanticscholar.org/CorpusID:254823489) and Reinforcement Learning from AI Feedback (H. Lee et al., 2024ReferenceLee, H., Phatale, S., Mansoor, H., Mesnard, T., Ferret, J., Lu, K., Bishop, C., Hall, E., Carbune, V., Rastogi, A., & others. (2024). RLAIF vs. RLHF: scaling reinforcement learning from human feedback with AI feedback. Proceedings of the 41st International Conference on Machine Learning, 26874–26901.). Both approaches shift critical alignment decisions from data contributors to more centralized authorities: namely, the LLM-as-a-Judge, and those who prompt it. For example, in Constitutional AI, models judge their own output against the standards of a human-written constitution, and then re-write a better, constitution-aligned response. Anthropic’s original 2022 constitution was sourced from Western liberal-democratic sources like the United Nations Declaration of Human Rights, the OECD, and Google’s AI Principles. These frameworks employ individualist, rights-based moral reasoning (Haidt, 2012ReferenceHaidt, J. (2012). The righteous mind: Why good people are divided by politics and religion. Vintage.), which may not represent other global ethical traditions, or incorporate the voices of pluralistic user bases (Sorensen et al., 2024ReferenceSorensen, T., Moore, J., Fisher, J., Gordon, M., Mireshghallah, N., Rytting, C. M., Ye, A., Jiang, L., Lu, X., Dziri, N., & others. (2024). A roadmap to pluralistic alignment. ArXiv Preprint, abs/2402.05070. https://arxiv.org/abs/2402.05070).